很多人咨询我,手机上到底有哪些计算摄影的应用和技术。那么接下来就准备抽空写一系列文章做一下介绍。
今天这一篇先从“人像模式”讲起,因为不管你现在是用iphone,还是小米,华为,OPPO, VIVO,以及其他几乎所有品牌的手机,都已经能用这个功能了。我们来好好捋一捋,这个功能内部到底有哪些计算摄影的技术在支撑。
手机上的人像模式,也被人们称作“背景虚化”或 ”双摄虚化“ 模式,也称为Bokeh模式,能够在保持画面中指定的人或物体清晰的同时,将其他的背景模糊掉。这样,画面的主体部分会显得突出,主观上美感更强烈。
下面是一张展现在专业评测网站dxomark.com上的华为P50Pro的人像模式所拍摄的照片,以及细节。

下面是另外一些我这边团队制作的图像(输入是小米8手机拍摄的,算法是我们自己的算法):


我想,不用我做过多解释,你看到这样的照片时也能体会出其中的吸引人之处了。
最早将这个功能带入到手机领域的,是2014上半年发布的HTC One M8, 当时它打出的卖点是“先拍照后对焦",当然实际效果用现在的标准看只能是惨不忍睹。但它的确吸引了业界的注意,陆续有公司开始研究这个技术了。

我自己差不多也是在2014年下半年开始实际在工作中研究和开发这个算法的。虽然那时候各家算法提供商,包括我们自己都还做得很不怎么样,但那时候,我们就提出了对这个功能的一些关键评价维度。如下图所示:

首先,这个功能就是用于突出主体的,所以对焦平面所在的主体一定要清晰,不能有丝毫的失焦模糊。与此同时,还需要符合光学规律,需要景深范围合理。比如与焦平面多大距离范围内的物体是清晰的,就很值得研究。这一点,其实并不那么容易,待会我会提到。

为了能够突出主体,在景深范围之外的部分则需要按照光学规律逐渐的模糊。很多人以为只是对背景区域做个简单的高斯模糊就能实现这种效果,然而并非如此。要真的能逼近单反的大光圈产生的这种效果,需要考虑的问题很多。这包括了画面中每一个像素的虚化程度、以及虚化方式的设计,还需要能够在手机这种计算量有限的平台上高效的实现。我们待会会看到更多技术方面的考量。

主体和背景、前景的边缘的表现对最终图像的美感和真实性影响非常大。这里我们要求的是主体和位于其后的背景的边缘要非常锐利,相互不会渗透和污染到对方。

而如果对焦主体远离相机,位于其前方、靠近相机的物体和主体的边缘则恰恰相反,应该呈现出特别的模糊感:

正如上面所说,我们希望画面在清晰和模糊之间的变化是符合光学规律的。于是随着非主体部分逐渐远离对焦平面,其模糊程度也应该是平滑渐变的。这显然就不是对这些区域简单做一个高斯模糊能做到的,而是需要更加复杂的渲染算法。

真实的光学系统在大光圈成像时,除了刚才提到的主体之外的模糊,还会在某些高光像素处形成特别质感的光斑,如下图所示。这些光斑随着与对焦平面的距离,甚至光轴的距离不同,还会呈现出不同的透明度、尺寸、形态、颜色。


小小的总结一段:
看似简单的一个“人像模式”功能,但是要做到逼真、有美感,需要在上面所说的几个维度上达到很高的水准才行。而要做到这一点,非常的不容易。即便到了现在,各家公司的算法都还在演进中,因为都还不能确保百分之百的仿真了单反的效果。就比如你用最新的Iphone,在某些场景下拍摄依然会发现出现一些真实单反不会出现的问题。特别是在主体有小细节、小镂空,或者背景是重复纹理、无纹理的情况。比如刚才我展示的这种网格场景,对算法就是一种考验。

现在我们来看看,这种技术是如何实现的。我在文章31. 镜头、曝光,以及对焦(上)中描述了相机的"景深"的概念

这里引用一下文章中的内容:
事实上,从物体上一点发出的光线通过透镜后,最终在像平面上会变成一个二维投影,如果镜头是圆形的,那么这个投影就是圆形的。我们通常称这个投影为模糊环(Circle of Confusion)。当恰好对焦时,模糊环的直径为0,那么我们看到的就是一个点。而当像平面不动,物点逐渐偏离可以恰好对焦的平面时,我们就会观察到像点逐渐变成了一个圆(或者其他镜头形状的投影)。注意这里由于人眼视力和感知的因素,当模糊环直径还没有超过某个阈值时,我们还认为投影是一个点,即成像还是清晰的,只有超过这个阈值时,成像才会变得模糊。这个阈值,我们称之为允许的最大模糊环,即Permissible Circle of Confusion。

根据景深计算公式,景深是和光圈值大小成线性关系的,光圈值越小,景深越小,反之越大。(小驰笔记:这里描述应该有误,“光圈值越大,景深应该是越小“。)

与物距成二次方关系,所以物距越远,景深越大

和焦距的平方成反比,所以焦距越大,景深越浅。长焦镜头看到的图像背景更加的模糊。

CoC和光圈值之间是呈现一种倒数关系,正如wikipedia所介绍的:
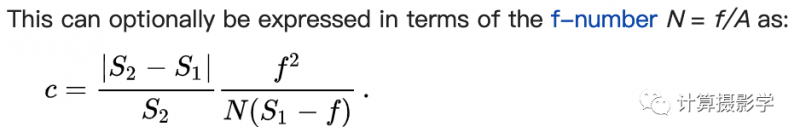
下图是一个形象的例子,展示了Canon 5D Mark III对焦到5m处物体时,CoC和场景中物距的关系:

所以,为了能够模拟出真实相机的大光圈的模糊效果,我们需要根据当前场景计算出每个像素的CoC——而这就意味着我们必须知道每一个像素对应的场景点与镜头的距离,或者这些场景点和对焦平面之间的距离。
这就引出来一个关键问题:如何知道镜头与场景点的距离呢?
获取场景中任意一点和镜头之间的距离,有很多不同的方法。比如我之前在52. 光的飞行时间技术 (TOF系列2)中讲到的TOF技术,就是一种很好的获取场景深度的方法。TOF技术获取的深度非常准确,然而它也有一些天然的缺点。例如室外使用时易受干扰,探测距离和功耗正相关等等。至少在这么几年来,量产的手机几乎都没有采用TOF这类主动的深度探测技术,而绝大多数是采用了被动式的双目立体匹配技术。
我们看到下面左图中,  是相机的成像平面,O是相机的光心。空间中的P和Q点都位于同一条穿过光心的直线上,于是它们在 平面上会投影到同一个点上——这就使得已知投影点p或q,我们很难判断它到底是从空间中的哪一点投影过来的。
是相机的成像平面,O是相机的光心。空间中的P和Q点都位于同一条穿过光心的直线上,于是它们在 平面上会投影到同一个点上——这就使得已知投影点p或q,我们很难判断它到底是从空间中的哪一点投影过来的。

而如果我们采用两个相机,如上面右图所示。那么在左边相机无法区分的投影点p和q,却可以在右相机的成像中区分出来。事实上,当采用两个相机时,空间中的P、Q两点,以及两个相机和对应的投影点之间的几何关系就会满足所谓的“对极几何约束”:

这事实上意味着我们能够通过这种约束关系,求出P、Q点与相机之间的距离!
为了让这种计算更加简单、直接,图像通常会先进行校正,变成所谓的标准形态,如下图黄色部分所示:

此时,一对图像中的对应着同一个空间位置的投影点,会变成位于同一条水平线上:

其对应的几何关系就会变得更加简洁了,如下图所示P为空间中一点,它和两个焦距为f的相机的距离为Z,它在两个相机成像平面上的投影点是p和p',其横坐标分别为XR和XT。

通过简单的相似三角形的计算,你很容易知道这个距离Z

这里面, d = X_R - X_T叫做视差,而b是两个相机光心的距离, f是焦距。这样,求取空间点和相机之间距离的关键就变成了求取其投影点视差了。而整个图像上所有点的视差构成了一幅图像,这个图像叫做视差图,如下所示:

而通过校正后的一对图像获取到视差图的过程,叫做立体匹配,它有点像玩连连看的游戏:给计算机一对输入图像,指定左图上的某个点,要求算法在右图上找到它对应的投影点,然后将两个点的横坐标相减得到该点的视差。
听起来很简单,是吧?然而,这个看起来简单直接的想法在现实中却会遇到很多问题。例如:


另外,图像中细小的边缘、镂空等等,也会对视差图的准确获取造成干扰。比如上面展示的铁丝网图像,算法就很容易出错:

也因此,准确的立体匹配算法就成为了几十年来人们一直在研究,即便到了深度学习大行其道的现在也依然热门的一个领域。这个领域如此热门,因此也就有了大量的开源代码。你可以通过OpenCV这样的计算机视觉库获取到基础而传统的立体匹配算法,也可以上Paper With Code这样的公开网站获取到更强大的立体匹配算法代码。然而要在真实的手机项目中落地,实际上有大量的工作需要做,才能解决误差以及泛化性问题。
我所带的团队,目前已经开发出了非常精细的基于深度学习的立体匹配,能够在极端挑战的场景稳定的获取到准确的视差图。下面展示一些例子,并和OpenCV自带的SGBM的运行结果做了对比:
小猫站在桌子上,注意猫胡子对应的视差图,纤毫毕现:
校正后的彩色左图与右图:

视差图:(左:OpenCV中的SGBM结果, 右: 我们的算法结果)

注意看我方视差图中的猫胡子,以及猫身视差的平滑及一致性
再来一只肥猫

视差图:(左:OpenCV中的SGBM结果, 右: 我们的算法结果)
注意看我方视差图中的猫胡子,以及猫身视差的平滑及一致性

之前说过,镂空场景也非常挑战算法。这是我们在一个场景的结果:

视差图:(左:OpenCV中的SGBM结果, 右: 我们的算法结果)

这些图片都来自于Holopix50k, 如果你对立体匹配也感兴趣,可以从下面的链接查看我放入的上面几张原始图片文件,还可以和我们的算法PK一把 :
链接: pan.baidu.com/s/1z65fQd 提取码: 2527
说到这里,你可能又会产生一个问题:刚才说过的将双摄像头拍摄的图片从普通形态转换成标准立体形态(如下图黄色所示),是如何做到的呢?这就不得不提到相机的标定和立体校正了。

我们看到上图中,两个所拍摄的图像,以及实际场景点,是在对极几何约束下的。在未进行立体校正时,图像上的对应点p与p’, q与q'通常不在两个图像的同一行上。而标准立体形态的p和p',q及q'则需要在同一行上。为了做到这点,需要获取到两个相机的空间几何关系,这包括了两个相机的三维旋转角度,以及两个相机的空间平移。与此同时,标准形态还要求图像是没有畸变的,这就是说我们还需要两个相机的焦距、图像中心、畸变参数等用于去畸变,以及将两个相机转换到同一个坐标系中。
在上面这些我们需要知道的信息中包括了两类参数:内参数与外参数
相机的焦距、图像中心、畸变参数等,叫做内参数
两个相机的旋转和平移信息,叫做外参数
而获取这些参数的过程,叫做双目相机的标定。而现在最著名的标定方法是“张正友标定法”,它通常要求拍摄不同距离、不同角度的几十张下面这种棋盘格的照片,然后通过特定的最优化迭代求解,获取到相机的内外参数。

这种标定方法,配合到高精度的棋盘格,可以获取到比较准确的标定结果。然而在手机的生产过程中,它却是不太现实的,因为繁琐、速度慢——你想想自己拿着手机拍十张不同角度、不同距离的棋盘格的图片需要多久。
我举个实际的例子,2021年5月21日,小米手机通过官方微博正式宣布,小米11系列全球销量突破300万台。这只是一个厂家的一款手机,所有手机厂商在同一段时间需要在工厂生产的手机何止千万台,如果都需要采用这种复杂的标定方式,那么无论哪个工厂的产能都会爆仓。于是,算法提供商的一个重要工作,就是对张正友标定法作出改进,在保证精度的基础上提高效率,现在据我了解手机的生产工厂可以稳定达到10到15秒的时间内标定两台手机的速度。
我们刚才讲述的内容总结如下图红框所示,最后一步COC计算得到的结果会送入到图像渲染模块,最终渲染出人像模式下背景虚化的图像。

然而,即便是有了准确的COC图,在图像渲染部分还会遇到很多困难。比如:
速度,如何在很短的时间(高端手机几十毫秒)内完成现在动辄上千万像素的图像
美观性,如何尽量逼近真实单反所拍摄的图像
为了提升美观性,通常是通过CoC的尺寸生成足够逼真的模糊核,然后对图像进行卷积操作来得到。最基础的做法是用纯圆形的模糊核:

虽然这样已经足以得到还算OK的渲染图像,然而真实的单反的模糊核有一些特点,无法用简单的圆形模糊核来模拟:
前景和后景的模糊核形态不一致
比如下图展示了单反的前景模糊核和背景模糊核在色散、透明度等方面的不同。


单反采用的镜头的机械结构,使得很多时候模糊核是非圆形的,下面是示意图:

另外,简单的卷积渲染得到的图像会在主体和背景的交界处,产生一种颜色泄漏的现象,如下图所示,非常难看。这是因为简单的卷积操作将位于主体和背景的像素加权平均到一起导致的。

当用物体的深度为基础计算加权权重后,问题可以得到解决,当然这也就带来了一定的计算量:

刚才提到了速度,我们知道一个基本的卷积操作,其计算量可以不严谨的表示为O(W*H*m*n),其中W为图像的宽,H为图像的高,而m和n则分别为卷积核的宽高,所以其计算量是很大的。于是就有很多学者研究了各种各样的方法来在保持美观的情况下,提升速度。我在参考资料中放了一篇这方面的综述,供你参考。
正如我在上面讲到的,一个对最终消费者来说看起来很简单的功能(甚至被很多人忽视的功能),其中却包含了好几个非常重要和基础的计算摄影的组件。

从一开始的HTC One M8,到现在的华米OV以及苹果的旗舰机器,产业界的各个角色一直在致力于将人像模式
模式越做越好,越做越实用。这里面包括了很多人的不懈努力:手机厂商作为客户一直在努力提出更高更贴近用户的要求,算法公司不断在努力给出更高效、更完美的解决方案,镜头模组厂不断努力生产更有利于最终效果的双摄模组,手机生产工厂则不断提升标定的准确度和效率。我很荣幸作为算法公司的一员,参与到了整个产业界从零开始精益求精打磨这个功能的过程中——从某种意义上讲,这也体现出来了所有这些组织和个人的工匠精神
在手机工业界不断打磨更好的基于双摄的成熟的人像模式的同时,工业界和学术界也在不断的推出更前沿的技术方案。比如传统上,我们需要通过双目立体匹配获取到场景的深度图,因为正如我前面所述,传统计算机视觉理论认为我们无法通过单个相机恢复出场景的深度。然而现在我们已经可以通过单个摄像头,通过深度学习训练,获取到场景的深度图了,就像下面的样张:


目前单目的深度算法还无法得到非常精细的细节,但是它却是颠覆性的技术,能解决现在双目立体匹配一些很难解决的问题。我们已经在特定客户项目上部署量产了这个功能,获得了客户的认可,将来它很可能用于更多的手机项目。
另外,学术界走得要更远一步。比如AIM Rendering Realistic Bokeh Challenge,已经举办了两届。这个比赛要求算法输入单帧图像,然后通过运算直接输出符合真实美感的背景虚化图像——这要求深度图计算,甚至最终的渲染都直接是在单张图像上进行的,大多数参赛队伍选择了基于深度学习的方案。虽然当前我们看到的结果还有诸多让人不满意的地方,但这焉知不是下一个爆发点?
小小一个功能,竟然引来这么多人的努力,使用了这么多高级的计算摄影的技术手段,确实让人感到惊讶。现在这个过程中的成果,例如准确的立体匹配或单目深度获取技术,显然是可以外溢到别的领域,例如自动驾驶领域的。期待看到技术的不断进步!
本文写作过程中,获得了好些同事的帮助,在此表示感谢。另外感谢美女模特提供了素材,整个文章的颜值都提升了不少
专业评测网站dxomark.com上的华为P50Pro的人像模式所拍摄的照片
Holopix50k: A Large-Scale In-the-wild Stereo Image Dataset
在背景虚化这件事上双摄手机距离相机还有多远?
Masaki Kawase, Recipes for Optical Effect System Design, Real-time Rendering of Physically Based Optical Effect in Theory and Practice, SIGGRAPH 2015 Course
Masaki Kawase, Making Your Bokeh Fascinating, Real-time Rendering of Physically Based Optical Effect in Theory and Practice, SIGGRAPH 2015 Course
Stanford 2010 Winter Computational photography CS 448A, Limitations of lenses
31. 镜头、曝光,以及对焦(上)
Stefano Mattoccia, Stereo Vision: Algorithms and Applications
Neal Wadhwa et al, Synthetic Depth-of-Field with a Single-Camera Mobile Phone, 2018
AIM Rendering Realistic Bokeh Challenge
技术交流2群,欢迎扫码加入:


推荐阅读:
一篇文章带你了解Android 最新Camera框架
这可能是介绍Android UvcCamera最详细的文章了
深圳上班,
生活简简单单,
从事Android Camera相关软件开发工作,
做过车载、手机、执法记录仪......
公众号记录生活和工作的点滴,
点击关注“小驰笔记”,期待和你相遇~