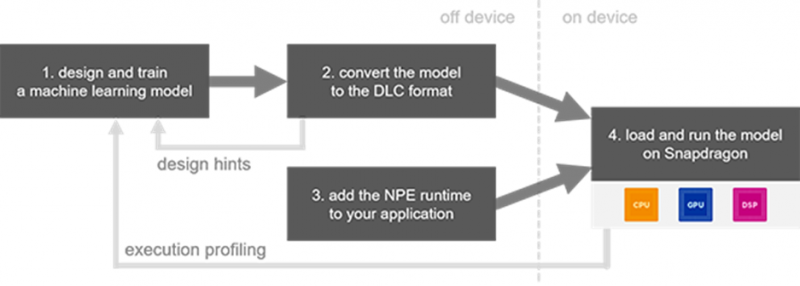
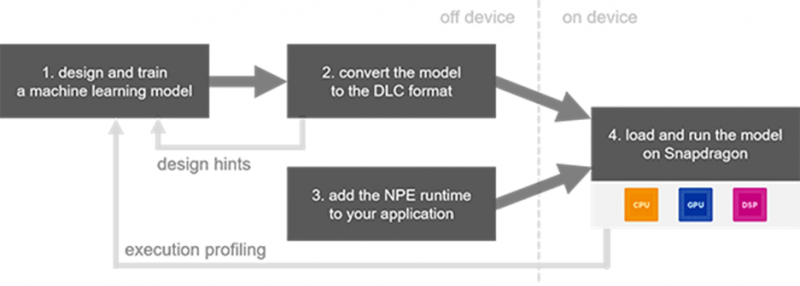
SNPE 是神经网络在骁龙平台上推理的开发套件,方便开发者在使用高通芯片的设备上加速AI应用。
无论是芯片制造商的发布会还是各大厂商的手机发布会,AI能力一直是大家谈论的焦点。
骁龙888采用了新一代的Hexagon 780架构Hexagon Tensor Processer(HTP),算力从865的15TOPS提升到了26TOPS,888+ 进一步提升到了32TOPS,尽管高通没有提供算力的细节,但从TOPS数值来看,确实很强大。
那么作为开发者,有没有办法使用HTP加速自己的AI模型推理呢?答案是肯定的,下面我们来一起探索如何使用888的HTP推理inceptionV3。
本文包含以下两部分。
- 使用手机的CPU和GPU推理inceptionV3
- 使用SNPE工具在HTP上推理inceptionV3
首先,我们用手机的CPU和GPU做模型推理,并记录他们的推理速度。这里我用搭载888的Redmi K40 pro开始。
(1)模型和数据采用上一篇 上手SNPE-推理inceptionV3 准备好的inception_v3.dlc 和 data
- 将数据和模型推到手机/data/local/tmp/incpv3
(2)准备SNPE对应的库libSNPE.so和测试工具snpe-net-run
- 将需要的SNPE库libSNPE.so,libc++_shared.so和测试的应用snpe-net-run推进手机 /data/local/tmp/incpv3/
(3) 在CPU和GPU上推理inceptionV3
- 在adb shell 里设置环境变量
- 在CPU上推理inceptionV3, 输出在output_cpu
- 在GPU上推理inceptionV3, 输出在output_gpu. snpe-net-run --use_gpu
- 解析SNPEDiag.log 得到CPU和GPU的推理速度.
pull outputs 到主机
用snpe-diagview 解析SNPEDiag.log 得到推理的时间

测试结果是在单一手机上的默认设置得到,并不代表任何性能指标
(1)量化模型
- 由于888 HTP仅支持定点INT8和INT16推理,所以需要对模型做量化,这里使用INT8。
- SNPE 提供了后量化工具 snpe-dlc-quantize.
- 加上选项--enable_htp,这样会针对888HTP生成一些cache数据,提升初始化速度。这个选项具有版本依赖性,如果更换了SNPE的版本,那么需要重新生产cache。
- 一般后量化需要的样例数据在100-200,这里仅仅演示功能,采用较少的数据。
(2)准备888 HTP 需要的dsp库
- libsnpe_dsp_domains_v3.so
- libsnpe_dsp_v68_domains_v3_skel.so
(3)在888 HTP上推理inceptionV3
- 设置环境变量,除了LD_LIBRARY_PATH和PATH之外,需要设定ADSP_LIBRARY_PATH来指向libsnpe_dsp_v68_domains_v3_skel.so 的路径。
- snpe-net-run --use_dsp
- 出现错误 The selected runtime is not available on this platform
- 这是因为商用手机只给开发者开放了HTP 的 unsignedPD( 具体可以参考Hexagon DSP SDK , 里面详细介绍了什么是unsigned PD),需要加上如下选项。
- snpe-net-run --use_dsp --platform_options unsignedPD:ON
(4)推理速度的比较
依然用snpe-diagview 解析SNPEDiag.log 得到推理的时间
这里每层的时间单位不是us, 应该是cycles
- 结果显示,888的HTP推理一次inceptionV3的时间是10.7ms.
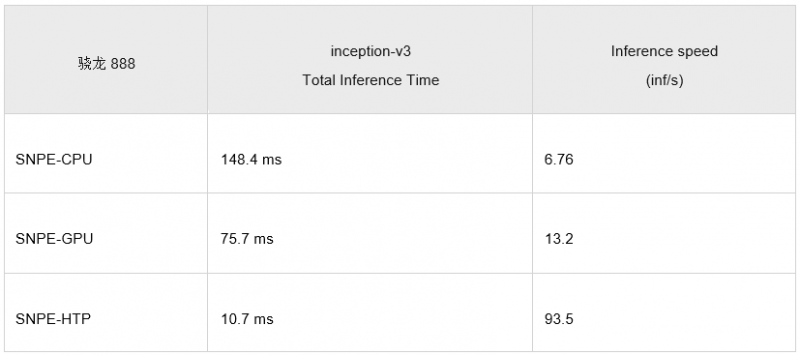
测试结果是在单一手机上的默认设置得到,并不代表任何性能指标。如果需要测试性能,需要设定性能模式和其他一些选项的设定,可以使用SNPE里面的snpe-throughput-net-run测试工具。
- 使用888手机的CPU和GPU推理inceptionV3
- 使用SNPE工具在888手机的HTP上推理inceptionV3
<path_to_snpe_sdk>/snpe-1.52.0.2724/doc/html/index.html