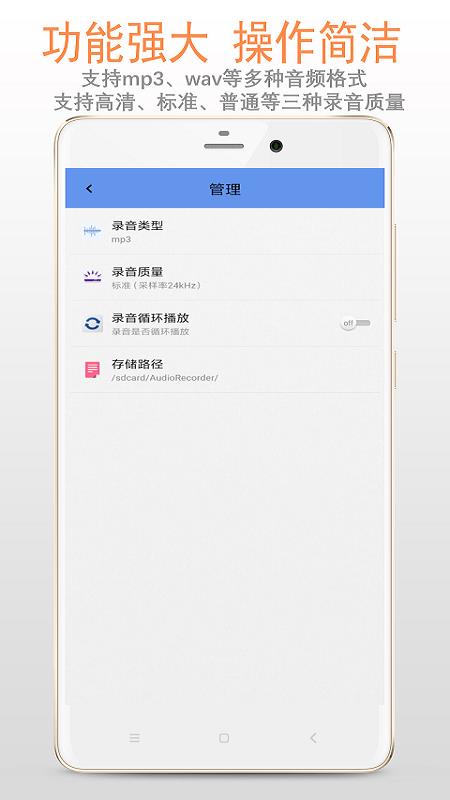
精品录音机是当下一款非常热门的系统工具软件,这款软件中具有超级丰富的实用性功能,这款软件可以帮助用户们解决手机带来的系统困扰,并且这款软件没有后台运行至不会偷流量,玩家们不用担心自己的隐私泄露,也不用担心软件内存扩大来消耗自己的内存,这款系统软件是非常具有广泛性和适用性的录音软件适合各种类型环境下的录音,录音效果也超级的清晰,完全不用担心,有太过复杂的杂音。
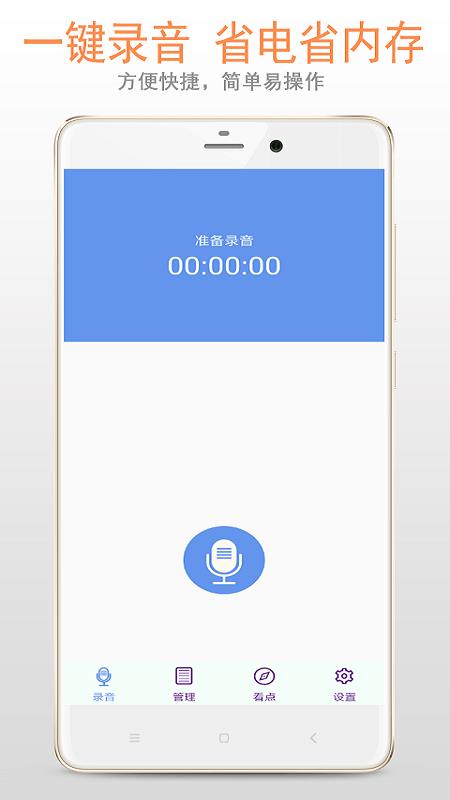
1.无需后台运行启动,超级迅速,随时随地可以进行录音,打开即可,录音无须过多操作,耽误时间。
2.这款录音软件支持中断,再录音不会将自己要录的东西变成两段,可以更加紧密地贴合在一起。
3.这款软件最大的卖点也是免费的,任何环境下,任何方式的录音或者简洁保存都可以是免费运行的,不用担心,会有收费。
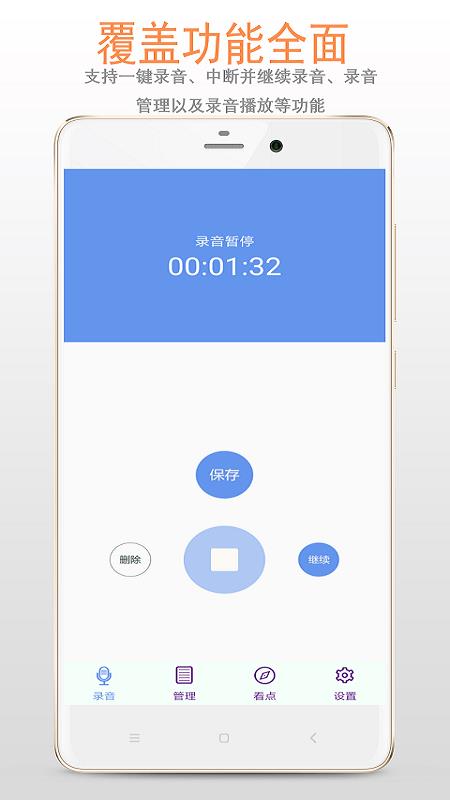
1.这款软件可以使用户门更加全方位的对录音文档进行保存和设置,可以简洁出自己需要的录音文件。
2.该软件适合各种音频格式,适用于各种手机类型,任何环境下都具有更高品质的录音效果。
3.随时随地即可分享,不占内存,不费流量,以最高品质服务用户,让用户有更多的录音体验。