
http://blog.csdn.net/pipisorry/article/details/76147604

深度学习在自然语言处理中第一个应用:训练词嵌入。Google 的 Tomas Mikolov 在《Efficient Estimation of Word Representation in Vector Space》和《Distributed Representations of Words and Phrases and their Compositionality》提出 Word2Vec,成为了深度学习在自然语言处理中的基础部件。目前官方最新的word2vec工具包发布于2013年,为c语言版本,此外还有非官方版本:python版本和java版本。
Word2Vec 的基本思想是把自然语言中的每一个词,表示成一个统一意义统一维度的短向量。至于向量中的每个维度也许对应于世界上的一些最基本的概念,但是是不可解释的。一个人读书时,如果遇到了生僻的词,一般能根据上下文大概猜出生僻词的意思,而 Word2Vec 正是很好的捕捉了这种人类的行为。
word2vec工具包输入是一个文本文件,称为训练语料,输出是一个词典,词典中包含训练语料中出现的单词以及它们的词嵌入表示。单词的词嵌入表示,就是用一个n维的实数向量来代表一个单词,单词之间的语义关系可以通过词嵌入体现出来,所以,要衡量词嵌入好与不好,可以观察词嵌入可以多大程度体现单词的语义信息。使用word2vec训练词向量的一个基本假设就是分布式假设,分布式假设是说词语的表示反映了它们的上下文,也就是它认为,有相似上下文的单词的语义也是相近的。
使用word2vec训练出的词嵌入有两个特点:
- 体现了语义相似关系。如计算距离“red”最近的词嵌入,结果就是“white”,“black”等表示颜色的单词。
- 体现了语义平移关系。如计算距离“woman”-“man”+“king”最近的词嵌入,结果就是“queen”。
在介绍word2vec前,先介绍一些基础知识,包括词向量和语言模型。然后介绍word2vec训练词嵌入时可以选择的四种模型,分别介绍它们的模型结构,以及使用梯度更新训练过程的数学推导。
NLP(Natural Language Processing)问题要转化为机器学习的问题,首先就要把单词数学化表示,就是用n维实数向量来代表一个单词,常见的词向量有以下两种:
独热编码One-hot Representation
例如: “话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …],“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]。
One-hot表示使用了单词在词表中的编号信息,编码方式如下:向量长度为词表大小,单词在词表中的编号对应的那一个维度为1,其余为0。
One-hot表示存在两个问题:
1.维度比较大,尤其在用于神经网络的一些算法时,出现“维数灾难”。
2.词汇鸿沟:任意两个词之间都是孤立的,不能体现词和词之间的关系(因为编码过程仅仅使用了它们在词表中的编号信息)。
分布式表示Distributional Representation
例如: [0.792, −0.177, −0.107, 0.109, 0.542, …],每个维度用一个实数值表示
克服了One-hot表示存在的两个问题:
1.解决了维度大的问题:常见维度50或者100。
2.解决了“词汇鸿沟”问题:可以通过计算向量之间的距离(欧式距离、余弦距离等)来体现词与词的相似性。
Note: 当然one-hot矩阵也可以通过svd分解得到低维稠密表示。而且在数学上证明,是和word2vec等价的。但是svd分解计算量大,且没有深度学习那么变化多端
这样的词向量称为词嵌入(word-embedding),那么如何训练这样的词向量呢?我们可以通过训练语言模型的同时,得到词向量。
接下来本文将介绍语言模型的概念,并介绍几种常见的语言模型。
语言模型其实就是判断一句话是不是正常人说出来的。用数学符号描述为:
给定一个字符串“w1,w2,…,wt”,计算它是自然语言的概率p(w1,w2,…,wt) ,一个很简单的推论是:
p(w1,w2,…,wt)=p(w1)⋅p(w2|w1)⋅p(w3|w1,w2)⋅…⋅p(wt|w1,w2,…,wt−1)
简单表示为:p(s)=p(w1,w2,…,wt)=∏ti=1p(wi|Contexti)
从上面的公式可以看出,建立语言模型要解决的核心问题就是如何计算p(wi|Contexti)?
N-gram语言模型
该模型基于这样一种假设:某个词的出现只与前面N-1个词相关,而与其它任何词都不相关。整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。
常用的是二元的Bi-Gram和三元的Tri-Gram。高于四元的用的很少,因为训练它需要更庞大的语料,而且数据稀疏严重,时间复杂度高,精度却提高的不多。
怎么得到P(Wn|W1W2…Wn-1)呢?一种简单的估计方法就是最大似然估计(Maximum Likelihood Estimate)了。即P(Wn|W1W2…Wn-1) = (C(W1 W2…Wn))/(C(W1 W2…Wn-1))。剩下的工作就是在训练语料库中数数了,即统计序列C(W1 W2…Wn) 出现的次数和C(W1 W2…Wn-1)出现的次数。
一个bigram的例子,假设语料库总词数为13748:
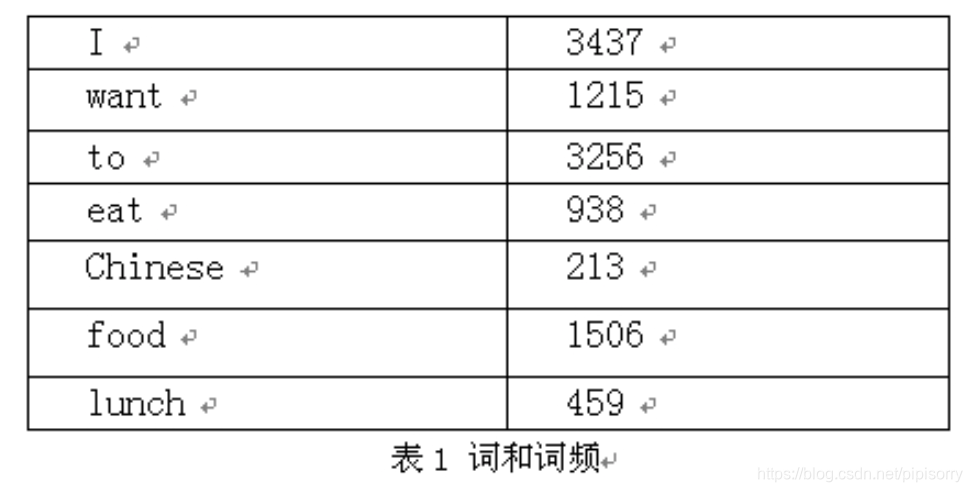
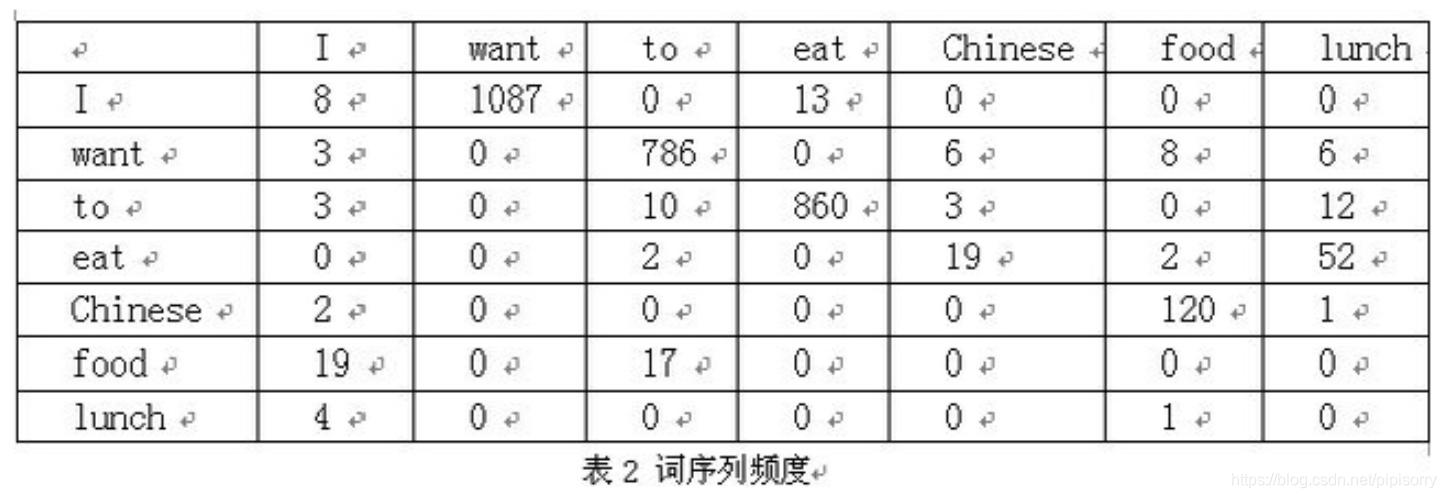
P(IwanttoeatChinesefood)=P(I)∗P(want|I)∗P(to|want)∗P(eat|to)∗P(Chinese|eat)∗P(food|Chinese)=(3437/13748)∗(1087/3437)∗(786/1215)∗(860/3256)∗(19/938)∗(120/213)=0.000154171
存在的问题:
稀疏问题:假设词表中有10000个词,如果是bigram,那么可能的N-gram就有100000000个,如果是trigram,那么可能的N-gram就有1000000000000个,对于其中的很多词对的组合,在语料库中都没有出现,根据最大似然估计得到的概率将会是0,这会造成很大的麻烦,在算句子的概率时一旦其中的某项为0,那么整个句子的概率就会为0,于是我们的模型只能算可怜兮兮的几个句子,而大部分的句子算得的概率是0。suffers from data sparsity and high dimensionality.
解决办法:数据平滑(data Smoothing):1. 添加平滑。分子+alpha/分母+alpha*词典大小|V|。2. 插值平滑。 3. Knerser Ney平滑技术。 4. 归一化,一个是使所有的N-gram概率之和为1,使所有的N-gram概率都不为0。5. 删除词频<=某个阈值如5。6.svd分解得到平滑版本。等等。
[N-gram模型]
有了N-gram,就可以将其作为上下文作为word的词稀疏表示,之后还可以通过svd分解什么的变成低秩稠密表示。
训练语言模型的最经典之作[Bengio, Yoshua, et al. "A neural probabilistic language model." JMLR2003]或者出版集中的[Bengio, Yoshua, et al. Neural probabilistic language models. In Innovations in Machine Learning. Springer, 2006]。
[Bengio, Yoshua, et al. "A neural probabilistic language model." JMLR2003]
Bengio 用了一个三层的神经网络来构建语言模型,同样也是 n-gram 模型(输入是固定N-1大小的窗口,即假设某个词的出现只与前面N-1个词相关)。 模型图中最下方的 wt−n+1,…,wt−2,wt−1就是前 n−1 个词。现在需要根据这已知的 n−1 个词预测下一个词 wt。
C(w) 表示词 w 所对应的词向量,整个模型中使用的是一套唯一的词向量,存在矩阵 C(一个 |V|×m 的矩阵)中。其中 |V| 表示词表的大小(语料中的总词数),m 表示词向量的维度。w 到 C(w)的转化就是从矩阵中取出一行。every word is mapped to a unique vector, represented by a column in a matrix W . The column is indexed by position of the word in the vocabulary. The concatenation or sum of the vectors is then used as features for prediction of the next word in a sentence. 就也是tensorflow中的embedding_lookup函数方法。
网络的第一层(输入层)是将 C(wt−n+1),…,C(wt−2),C(wt−1)这 n−1 个向量首尾相接拼起来(或者average也可以,如果average就和word2vec的cbow作法一样了),形成一个 (n−1)m 维的向量,下面记为 。 网络的第二层(隐藏层)就如同普通的神经网络,直接使用 d+Hx计算得到。d 是一个偏置项。在此之后,使用 tanh作为激活函数。 网络的第三层(输出层)一共有 |V|个节点,每个节点 yi 表示 下一个词为 i 的未归一化 log 概率。最后使用 softmax 激活函数将输出值 y 归一化成概率。
因为有直连边G(X)的存在(剩余网络嘛),输出层的输入可以描述为:y=b+Wx+Utanh(d+Hx) 。直连边的存在虽然不能提升模型的效果,但是可以少一半的迭代次数!整个模型的多数计算集中在 U 和隐藏层的矩阵乘法中。
其目标函数可以表示成:
模型优化求解
用随机梯度下降法把这个模型优化出来就可以了,需要注意的是,一般神经网络的输入层只是一个输入值,而在这里,输入层 x 也是参数(存在 C 中),也是需要优化的。优化结束之后,词向量有了,语言模型也有了。
θ = (b, d,W,U, H,C)
实现
如深度学习框架keras中的embedding层其实就是这个可训练的东西,将正整数(索引值或者one-hot什么的)转换为固定尺寸的稠密向量。 例如: [[4], [20]] -> [[0.25, 0.1], [0.6, -0.2]]。
[keras:3)Embedding层详解] 但是这个nn模型还是不够好,考虑的不周到,效果不行,所以就有了下面的word2vec。
-柚子皮-
word2vec工具包提供了四种可选的训练模型,分别是由两种模型(CBOW(Continuous Bag-of-Words Model),Skip-gram(Continuous Skip-gram Model)),两种方法(Hierarchical Softmax,Negative Sampling)组合而成。
CBOW模型:已知上下文wt−2,wt−1,wt+1,wt+2,预测当前词wt。对于一个样本,做一次预测,具体做法是:将所有的上下文单词的词向量加起来,得到投影层向量xw,由xw预测当前词出现的概率。
Skip-gram模型:已知当前词wt,预测上下文wt−2,wt−1,wt+1,wt+2。对于一个样本,做4次预测:直接使用当前词的词向量作为投影层向量,得到投影层向量xw,由xw分别预测每个上下文单词出现的概率。
使用h-softmax就是输出时,输出语料库V中所有词的概率分布,所以直接使用softmax计算会相当慢,要使用h-softmax。
基于H-softmax的CBOW模型
CBOW是一种与前面讲到的前向NNLM类似的模型,不同点在于CBOW去掉了最耗时的非线性隐层、并且所有词共享隐层。
H-S CBOW模型与NNLM的不同:
- (从输入层到投影层的操作)CBOW-求和累加/平均;NNLM-拼接
- (隐藏层)CBOW-无耗时的非线性隐藏层; NNLM-非线性隐藏层
- (输出层)CBOW-树形结构; NNLM-线性结构
NNLM的大部分计算集中在隐藏层和输出层之间的矩阵向量运算、输出层上的SoftMax归一化运算,CBOW模型对这些计算复杂度高的地方进行了改变:去掉了隐藏层、输出层改用Huffman树。
lz目标应该是最大化输出和真实的概率的交叉熵。Word2vec中采用的优化方法是随机梯度上升法(因为是要最大化)。
训练好后,词向量就是第一层网络的权重矩阵,即从输入层到隐含层的那些权重(等价于前面说的NNLM中的矩阵C)。
CBOW模型的解释
Word2Vec 的训练模型,是具有一个隐含层的神经元网络。它的输入是词汇表向量,当看到一个训练样本时,对于样本中的每一个词,就把相应的在词汇表中出现的位置的值置为1,否则置为0。它的输出也是词汇表向量,对于训练样本的标签中的每一个词,就把相应的在词汇表中出现的位置的值置为1,否则置为0。那么,对所有的样本,训练这个神经元网络。收敛之后,将从输入层到隐含层的那些权重(这等价于前面说的NNLM中的矩阵C:一般将物体嵌入到一个低维空间R^n(n<<m) ,只需要再compose上一个从R^m到R^n的线性映射就好了。每一个n*m 的矩阵M都定义了R^m到R^n的一个线性映射: x->Mx。当x 是一个标准基向量的时候,Mx对应矩阵M中的一列,这就是对应id的向量表示。[深度学习:Embedding]),作为每一个词汇表中的词的向量。比如,第一个词的向量是(w1,1 w1,2 w1,3 ... w1,m),m是表示向量的维度。所有虚框中的权重就是所有词的向量的值。
CBOW的做法是,将一个词所在的上下文中的词作为输入,而那个词本身作为输出,也就是说,看到一个上下文,希望大概能猜出这个词和它的意思(输入应该是n个上下文,所以有多个1,输出应该是1个当前词,所以有1个1)。通过在一个大的语料库训练,得到一个从输入层到隐含层的权重模型。如下图所示,第l个词的上下文词是i,j,k,那么i,j,k作为输入,它们所在的词汇表中的位置的值置为1。然后,输出是l,把它所在的词汇表中的位置的值置为1。训练完成后,就得到了每个词到隐含层的每个维度的权重,就是每个词的向量。
[如果看了此文还不懂 Word2Vec,那是我太笨]
H-softmax的解释
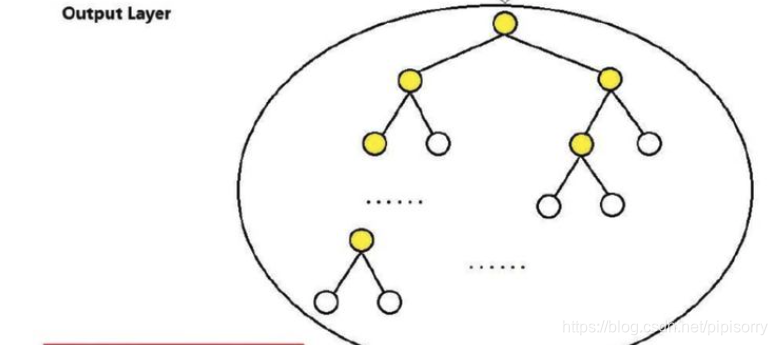
上图输出层的树形结构即为Hierarchical Softmax。
每个叶子节点代表语料库中的一个词,于是每个词语都可以被01唯一的编码,并且其编码序列对应一个事件序列,于是我们可以计算条件概率 p(w|Context(w))。
在开始计算之前,还是得引入一些符号:

也就是说,H-softmax学习的是树结构里面每个结点的概率(节点数少),每个word的概率通过结点路径表达(路径数多),这样就减少了计算量。
Note:
1 如果不用层次softmax,则要先计算所有词的softmax分并加和,再算输出词/这个和归一化,然后-1算loss。 2 用层次softmax,则只需要算输出词的路径上的乘积(只有所有词个数的log(n)次计算),然后-1算loss。 3 softmax只是用于加速预测词的最终归一化分的计算的,与embedding(在第一层表达输入的emb)无关。
[Hierarchical Softmax(层次Softmax)]
Hierarchical Softmax加速
如同fastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
[Hierarchical Softmax --CBOW]
后面发表论文的 3 个工作,都有对这一环节的简化,提升计算的速度。(fastText 模型也是使用层次softmax)
如In practice, hierarchical softmax (Morin & Bengio, 2005; Mnih & Hinton, 2008; Mikolov et al., 2013c) is preferred to softmax for fast training.
[Morin, Frederic and Bengio, Yoshua. Hierarchical probabilistic neural network language model. Aistats2005] [Mnih, Andriy and Hinton, Geoffrey E. A scalable hierarchical distributed language model. In Advances in Neural Information Processing Systems2008]
the structure of the hierarical softmax is a binary Huffman tree, where short codes are assigned to frequent words.[Mikolov, Tomas, Sutskever, Ilya, et al. Distributed representations of phrases and their compositionality. NIPS2013c]
代码code.google.com/p/word2vec/ [Mikolov, Tomas, et al. Efficient estimation of word representations in vector space. arXiv 2013a]
基于H-softmax的Skip-gram模型
与CBOW模型的推导过程大同小异。基于层次SoftMax的skip-gram模型的网络结构如下:
基于negtive sampling的cbow word2vec模型架构
[Le, Quoc, and Tomas Mikolov. "Distributed representations of sentences and documents." ICML2014]
负采样Negative Sampling的解释
Negative sampling(NEG)可以视为对层次SoftMax的一种代替,它不再使用(复杂的)Huffman树,而是利用(相对简单的)随机负采样,其目的也是用来提高训练速度并改善所得词向量的质量。对比之前n个输出单元的softmax分类,negative sampling转化为k+1个二分类问题。
在CBOW模型中,已知词w的上下文Context(w),需要预测w,因此,对于给定的上下文Context(w),词w就是一个正样本,其他的词就是负样本。负样本太多了,因此我们需要某种方法选取适量的负样本NEG(x)。
负样本采样方法
1 通过单词出现的频率进行采样:导致一些类似a、the、of等词的频率较高
2 均匀随机地抽取负样本:没有很好的代表性
3 Word2vec采用带权采样法:词典D中的词在语料C中出现的次数有高有低,对于那些高频词,被选为负样本的概率就应该比较大,而低频词出现的概率应该比较小。
这种方法处于上面两种极端采样方法之间,即不用频率分布,也不用均匀分布,而采用的是对词频的3/4除以词频3/4整体的和进行采样的。其中,f(w_j)是语料库中观察到的某个词的词频。
[2.7 负采样(Negative Sampling)]
Ronan Collobert 和 Jason Weston 在 2008 年的 ICML 上发表的《A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning》。lz: 提出负采样的方法。
Andriy Mnih 和 Geoffrey Hinton 在 2007 年和 2008 年各发表了一篇关于训练语言模型和词向量的文章。2007 年发表在 ICML 上的《Three new graphical models for statistical language modelling》。2008 年发表在 NIPS 上的《A scalable hierarchical distributed language model》则提出了一种层级的思想替换了 Bengio 2003 方法中最后隐藏层到输出层最花时间的矩阵乘法,在保证效果的基础上,同时也提升了速度。lz:主要提出了Hierarchical Softmax。
使用循环神经网络降低Bengio 2003 论文中的参数个数。
w(t) 是句子中第 t 个词的 One-hot representation 的向量,也就是说 w 是一个非常长的向量,里面只有一个元素是 1。而下面的 s(t−1)向量就是上一个隐藏层。最后隐藏层计算公式为:
s(t)=sigmoid(Uw(t)+Ws(t−1))
w(t) 是一个词的 One-hot representation,那么 Uw(t) 也就相当于从矩阵 U 中选出了一列,这一列就是该词对应的词向量。
循环神经网络的最大优势在于,可以真正充分地利用所有上文信息来预测下一个词,而不像前面的其它工作那样,只能开一个 n 个词的窗口,只用前 n 个词来预测下一个词。
缺陷:用起来却非常难优化,如果优化的不好,长距离的信息就会丢失,甚至还无法达到开窗口看前若干个词的效果。
隐藏层到输出层的巨大计算量,Mikolov 使用了一种分组的方法:根据词频将 |V| 个词分成 |V|‾‾‾√ 组,先通过 |V|‾‾‾√ 次判断,看下一个词属于哪个组,再通过若干次判断,找出其属于组内的哪个元素。最后均摊复杂度约为 o(|V|‾‾‾√),略差于 M&H 的 o(log(|V|)),但是其浅层结构某种程度上可以减少误差传递,也不失为一种良策。
[Mikolov, Tomas, et al. "Recurrent neural network based language model." Interspeech2010] code [RNNLM 完美支持中文]
了解 RNNLM,参考其博士论文《Statistical Language Models based on Neural Networks》是最好的选择。
另外还提出上下文相关的语言模型。鉴于句子太长,历史信息无法有效传播。提出了一个RNN-LDA上下文依赖(topic-conditioned RNNLM)的模型,模型通过添加前面词的主题信息作为上下文。They augment the contextual information into the conventional RNNLM via a real-valued input vector, which is the probability distribution computed by LDA topics for using a block of preceding text.
[Mikolov, Tomas, and Geoffrey Zweig. "Context dependent recurrent neural network language model." SLT2012]
考虑语义+词序使用vector来表示paragraph,并用于情感分类和信息检索。propose Paragraph Vector, an unsupervised framework that learns continuous distributed vector representations for pieces of texts. The texts can be of variable-length, ranging from sentences to documents.
Distributed Memory Model of Paragraph Vectors (PV-DM), 类似CBOW。
Distributed Bag of Words version of Paragraph Vector (PV-DBOW),类似skip-gram。
实验中PV-DM模型效果很好,不过PV-DM和PV-DBOW一起用更好。
[Le, Quoc, and Tomas Mikolov. "Distributed representations of sentences and documents." Proceedings of the 31st International Conference on Machine Learning (ICML-14). 2014.]
word2vec作者对参数选取的建议
- Skip-gram更慢一些,但是对低频词效果更好;对应的CBOW模型则速度要快一些
- 层次SoftMax模型对低频词效果更好;对应的negative sampling对高频词效果更好,向量维度较低时效果更好
- 词向量的维度,一般越高越好,但并不总是这样
- 窗口大小的选择:skip-gram一般10左右,CBOW模型一般5左右
- 高频词negative sampling:对大数据集合可以同时提高精度和速度
优点
1. word2vec语言模型自带平滑,无需传统 n-gram 模型中那些复杂的平滑算法。Bengio 在 APNews 数据集上做的对比实验也表明他的模型效果比精心设计平滑算法的普通 n-gram 算法要好 10% 到 20%。
2.词语间的相似性可以通过词向量体现,例如:语料中S1=“A dog is running in the room”出现了10000,次,S2= “A cat is running in the room”出现了0次,按照n-gram模型的做法,p(S1)肯定远大于p(S2)。而在NNLM中,两者非常接近,因为cat的词向量和dog非常接近,将词向量代入计算得到的结果就很接近。
其他几种模型如C&W 的 SENNA,M&H 的 HLBL,Mikolov 的 RNNLM,Huang 的语义强化都是在Bengio论文发表后受到启发并进行一定改进的模型[Deep Learning in NLP (一)词向量和语言模型 – licstar的博客]。
Bengio 2003 使用了最朴素的线性变换,直接从隐藏层映射到每个词;C&W 简化了模型(不求语言模型),通过线性变换将隐藏层转换成一个打分;M&H 复用了词向量,进一步强化了语义,并用层级结构加速;Mikolov 则用了分组来加速。
from: 深度学习:词嵌入之word2vec_独热编码 词汇鸿沟_-柚子皮-的博客-CSDN博客
ref: [斯坦福大学深度学习与自然语言处理第二讲:词向量]
[]
[word2vec中的数学原理]**
[Deep Learning in NLP (一)词向量和语言模型]*