潮新闻客户端 记者 张云山
3月27日凌晨,阿里巴巴发布并开源首个端到端全模态大模型通义千问Qwen2.5-Omni-7B,可同时处理文本、图像、音频和视频等多种输入,并实时生成文本与自然语音合成输出。在权威的多模态融合任务OmniBench等测评中,Qwen2.5-Omni刷新业界纪录,全维度远超Google的Gemini-1.5-Pro等同类模型。
Qwen2.5-Omni以接近人类的多感官方式“立体”认知世界并与之实时交互,还能通过音视频识别情绪,在复杂任务中进行更智能、更自然的反馈与决策。现在,开发者和企业可免费下载商用Qwen2.5-Omni,手机等终端智能硬件也可轻松部署运行。
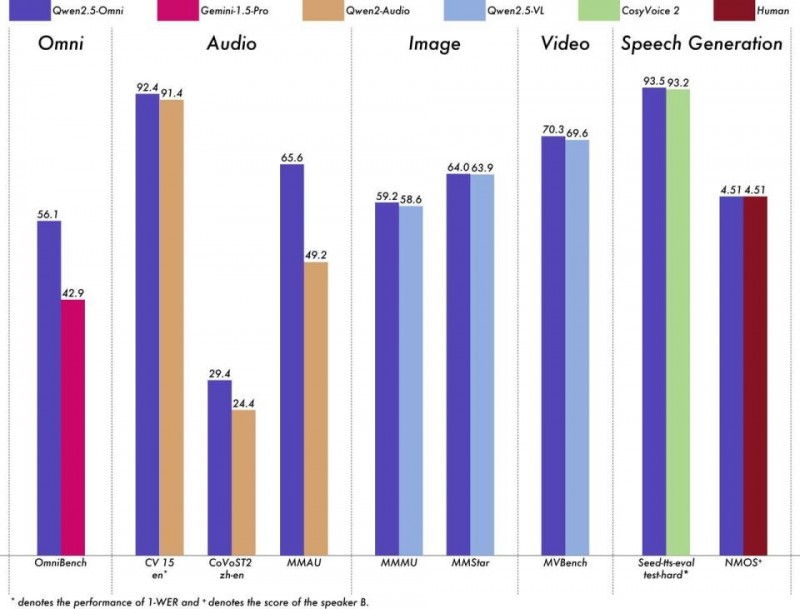
图示 性能测评对比
Qwen2.5-Omni采用了通义团队全新首创的Thinker-Talker双核架构、Position Embedding (位置嵌入)融合音视频技术、位置编码算法TMRoPE(Time-aligned Multimodal RoPE)。双核架构Thinker-Talker让Qwen2.5-Omni拥有了人类的“大脑”和“发声器”,形成了端到端的统一模型架构,实现了实时语义理解与语音生成的高效协同。具体而言,Qwen2.5-Omni支持文本、图像、音频和视频等多种输入形式,可同时感知所有模态输入,并以流式处理方式实时生成文本与自然语音响应。
得益于上述突破性创新技术,Qwen2.5-Omni在一系列同等规模的单模态模型权威基准测试中,展现出了全球最强的全模态优异性能,其在语音理解、图片理解、视频理解、语音生成等领域的测评分数,均领先于专门的Audio或VL模型,且语音生成测评分数(4.51)达到了与人类持平的能力。
相较于动辄数千亿参数的闭源大模型,Qwen2.5-Omni以7B的小尺寸让全模态大模型在产业上的广泛应用成为可能。即便在手机上,也能轻松部署和应用Qwen2.5-Omni模型。当前,Qwen2.5-Omni已在魔搭社区和Hugging Face 同步开源,用户也可在QwenChat上直接体验。