亲爱的宝爸宝妈们,国家卫生健康委发布“体重管理年”3年行动,咱们的“小肉墩拯救计划”有国家级攻略啦!快收下这份不费妈不费爸的趣味指南吧!
【吃吃吃攻略——舌尖上的智慧】
主食刺客防御方案
替换公式:每餐米饭/面条的1/3换成这些。
杂粮替身:燕麦饭、三色藜麦、黑米红豆粥(电饭煲一键搞定)
薯类替身:蒸南瓜块、山药泥、红薯丁(混进米饭里更香!)
饮料大魔王破解术饮料红绿灯清单
绿灯(随便喝):白开水、柠檬水、无糖豆浆
黄灯(每天1杯):100%果汁、无糖酸奶
红灯(每周≤2次):奶茶、可乐、含乳饮料
零食游击队歼灭计划家庭零食柜改造指南
必囤清单:原味坚果(每天1小把)、无糖酸奶+新鲜水果、低盐海苔
黑名单预警:蛋黄派、巧克力派、薯片、辣条(糖油炸弹!)

【运动指南——玩着瘦才是王道】
放电神器→每天60分钟中高强度运动
运动公式=基础任务+趣味副本
基础任务(上学日必做)
走路/骑车上下学
课间跳绳+课间操
趣味副本(周末解锁)
家庭挑战赛:跳绳连击赛(爸妈和孩子比连续不断绳次数)
公园闯关:设计关卡(如单脚跳过地砖缝→亲子赛跑→蹲跳→倒走……)
懒人运动包
下雨天方案:客厅家庭健身操(跟跳视频健身操)
写作业间隙:每30分钟做5个“课本深蹲”(举着书本蹲起)
【睡眠充电计划——躺着也能瘦】
21:30前入睡=启动生长激素充电模式
生长激素在22:00-2:00与5:00-7:00达到峰值,需确保儿童在此时段处于深度睡眠状态,晚于21:00入睡可能导致激素分泌不足,影响身高发育。
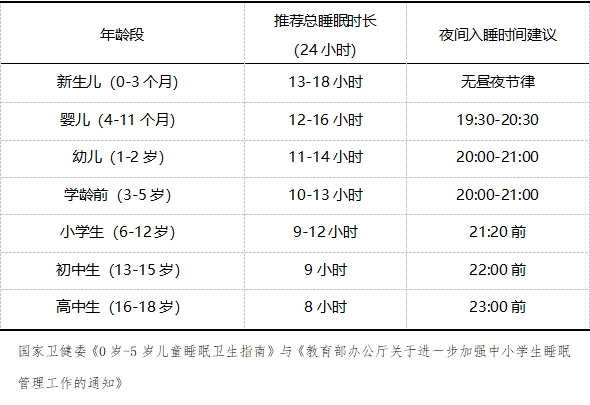
附:各年龄入睡时间表(科学长高又燃脂)
助眠小仪式
睡前0.5-1小时:调暗灯光+播放轻音乐
亲子暗号:和孩子约定“睡眠魔法咒语”(如“月亮骑士,准备变身!”)
【专家说重点】
体重管理不是饥饿游戏,而是全家升级打怪的过程!
6-17岁孩子每年应测身高体重4次,当体重增幅超过身高增幅要提前预警哦!
【举个例子】
小明家的一天
早餐:鸡蛋蔬菜卷饼(全麦饼+生菜+胡萝卜丝)+酸奶
运动:上学骑车+体育课踢球+课间操
午餐:杂粮饭+咖喱牛肉+炒时蔬+苹果
晚餐:玉米发糕+清蒸鱼+白灼菜心
运动:餐后散步+亲子羽毛球
睡前:21点全家熄灯,听《西游记》有声书入睡
行动TIP:从今天开始记录“健康银行存折”,每完成1项任务盖1个章,攒满30章换家庭奖励(如露营/博物馆一日游)!
快快展开拯救“小肉墩”行动吧,这个三年计划,咱们用爱发电不摆烂!