本题已收录至知乎圆桌:人工智能 · 语言智能,更多「人工智能」相关话题欢迎关注讨论
简要给大家介绍一下语音怎么变文字的吧。需要说明的是,这篇文章为了易读性而牺牲了严谨性,因此文中的很多表述实际上是不准确的。对于有兴趣深入了解的同学,本文的末尾推荐了几份进阶阅读材料。下面我们开始。
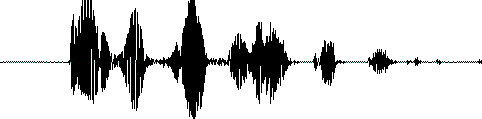
首先,我们知道声音实际上是一种波。常见的mp3等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如Windows PCM文件,也就是俗称的wav文件。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。下图是一个波形的示例。
在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成的干扰。这个静音切除的操作一般称为VAD,需要用到信号处理的一些技术。
要对声音进行分析,需要对声
楼上张俊博的回答比较仔细的讲解了基础的经典语音识别算法。我想对算法背后的含义做一个简单的解释,对涉及到的特征提取(包括分帧)、音素建模、字典、隐式马尔科夫模型等可以参阅楼上的回答。
语音识别的第一个特点是要识别的语音的内容(比声韵母等)是不定长时序,也就是说,在识别以前你不可能知道当前的 声韵母有多长,这样在构建统计模型输入语音特征的时候无法简单判定到底该输入0.0到0.5秒还是0.2到0.8秒进行识别,同时多数常见的模型都不方便处理维度不确定的输入特征(注意在一次处理的时候,时间长度转化成了当前的特征维度)。一种简单的解决思路是对语音进行分帧,每一帧占有比较短固定的时 长(比如25ms),再假
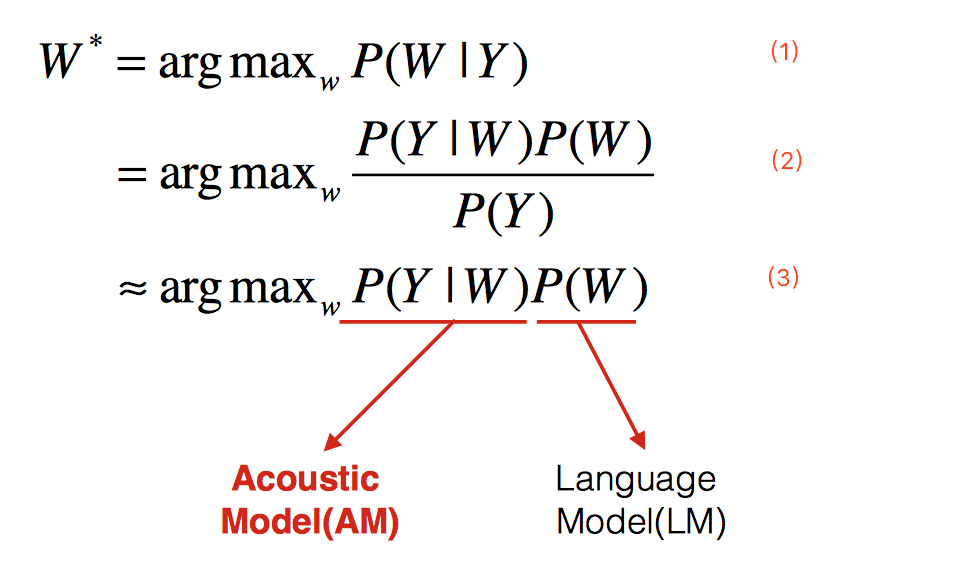
鉴于传统架构的语音识别方法在其他的回答中已经有了详细的介绍,这里主要介绍end-to-end语音识别架构,主要涉及到RNN神经网络结构以及CTC。
Outline:
1、 语音识别的基本架构
2、 声学模型(Acoustic Model,AM)
- a) 传统模型
- b)CTC模型
- c) end-to-end模型
3、 语言模型
4、 解码
----------------------------------------------------
1、 语音识别的基本架构